Why Designers Need Layers, Not Just Pictures!
Jaejung Seol, Elad Hirsch, Shubham Yadav, Purvanshi Mehta
TL;DR
Gen-AI is great at creating images, but professional design is about iterating on them, and today's models fall apart when edits are required. The core problem isn't creativity, it's editability: without decomposing images into high-fidelity, pixel-accurate layers, AI outputs behave like locked screenshots. This blog explains why image decomposition is hard, why naïve LLM-based editing drifts and degrades layouts, how the field is moving from iterative pipelines to end-to-end layered generation, and how Lica is building a hybrid workflow where AI generates and decomposes designs while designers retain full control over layers, typography, and precision.
Professional design work is fundamentally an iterative process: it demands pixel-accurate placement, strict typography rules, and brand consistency. Today's Gen-AI systems, however, are optimized for creative results rather than deterministic control. This mismatch creates a huge gap between the hype and reality: a 'design generation' tool might look impressive in a demo, but if the output behaves like a "locked screenshot," it is unusable in production.

In reality, professional design is 20% creation and 80% iteration. We see growing frustration from clients who can generate beautiful layouts in seconds but hit a wall when revisions are needed. If you can't isolate a headline to change a font without hallucinating other details, the workflow is unusable.
The missing link here isn't more creativity, it's decomposition. We need to bridge the gap between 'generated images' and 'layered and editable files'.
Recent advancements in such models such as LayerD and Qwen-Image-Layered frame this challenge as decomposing images into editable layer stacks, because without layers, professional editing is impossible.
At Lica, we are building the solution through a hybrid workflow. Instead of just a chat prompt, we are building a workspace where AI handles generation and decomposition, while designers retain absolute authority over its editability. This ensures the output is not just "generated," but truly designed, allowing users to tweak copy, reposition objects, and lock specific font files. This blog dives into why high-fidelity image decomposition is hard, and how Lica is making Gen-AI truly editable.
What is Image Decomposition?
Simply put, image decomposition means breaking down an image into its constituent parts - Images, text, svg vectors, etc.
A high fidelity decomposition would mean that when we put the components back together, in a perfect scenario it should match the original layout pixel by pixel.
Image Editing through LLMs
Before we jump to discussing the technical details of Image Decomposition, we need to have an honest answer about this - 'Why the focus on the idea of a pipeline? Why not just edit the image using Gemini or ChatGPT? Considering they could change the human images with such high fidelity where they are indiscernible, changing things on a layout should be a piece of cake right?'.
And I would agree with you, partly.
I won't deny that the current generation of models is impressive. I use them for quick editing tasks myself. But let me show you exactly why they haven't replaced professional design tools yet.
Here is what happened when I asked for a simple text edit on a sample layout:

And remember, this degradation happened after just one single prompt. With each pass, it starts drifting further and further. It's the digital equivalent of a photocopy of a photocopy: with every subsequent prompt, the error propagates, and the original design fidelity drifts further away.
In short, the stochastic (random) nature of LLMs, the very feature that makes them creative, is what makes them unreliable in 'layout preservation'. It's not a prompting issue, its an architectural one.
LLMs optimize for creativity, while professional design demands consistency.
For this task, we need to look at models who have specialized architectures and training setups for breaking down a layout into layers, so we could edit each of them independently without affecting the other layers.
SOTA Methods of Image Decomposition
The industry has lately tackled the challenge of decomposing an image through two main flows: a) Recursive breakdown and b) End-to-End generative approach.
The hard part isn't just "cutting the object out", it's reconstructing the image behind it. The system must generate what lies behind occluded regions and handle semi-transparency without losing pixel fidelity.
a) Recursive Extraction Approach
This approach follows an intuitive stacking logic: Extract the top layer, inpaint the exposed area, and repeat. Essentially a "Segment → Erase → Generate → Repeat" loop. While this is conceptually aligned with how we think about layers, this method suffers from error accumulation: Any imperfection in early masks propagates downward, degrading all subsequent layer outputs.
There are 2 ways to do this -
- Matting-Based (Classic): Great for hard edges but leaves jagged artifacts on transparency.
- Diffusion-Based (Generative): Uses diffusion to generate layers with soft transparency (alpha), handling "fuzzy" objects like hair or smoke much better.
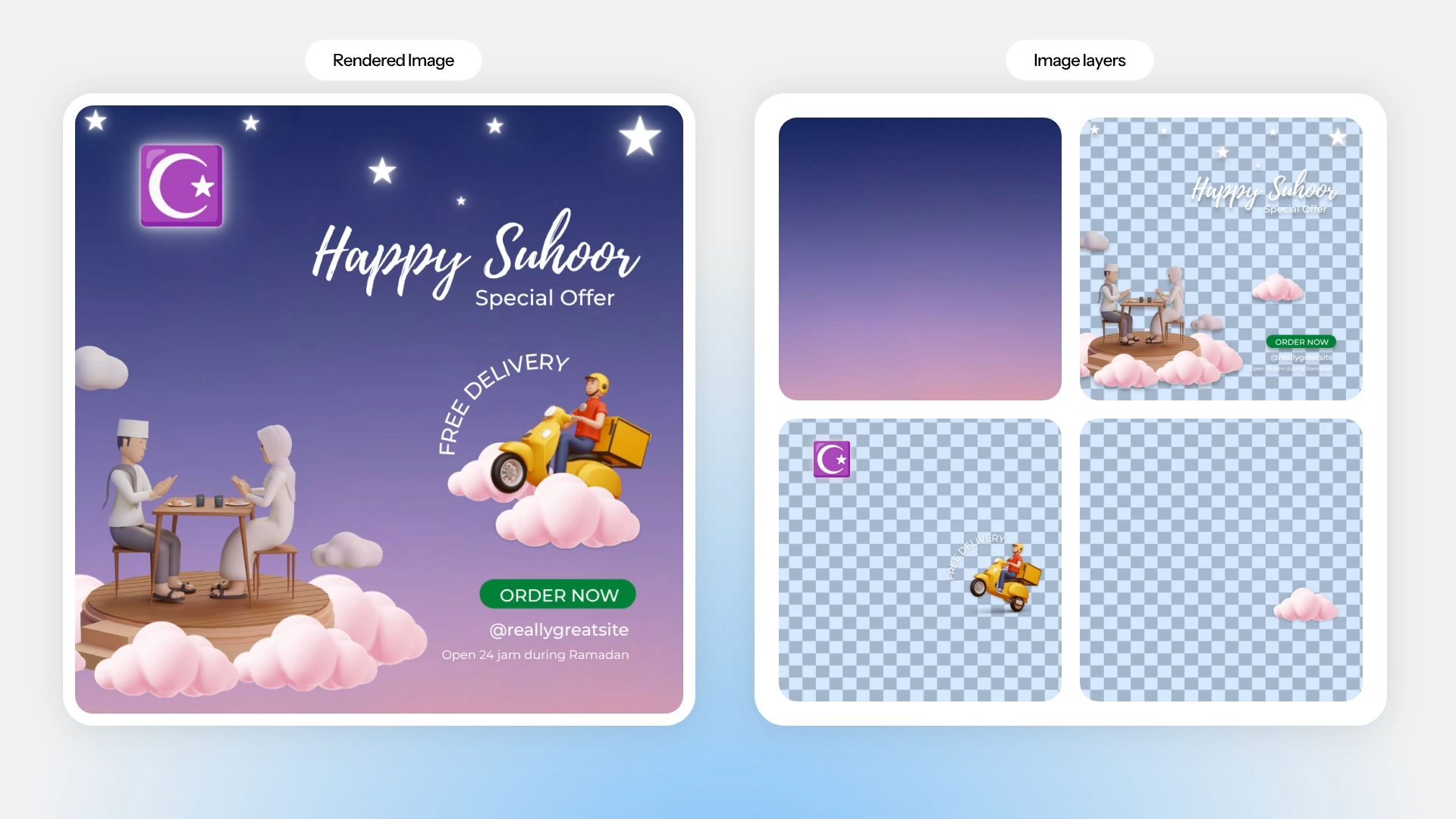
Recursive Extraction Approach using LayerD (https://cyberagentailab.github.io/LayerD/)
b) End-to-End Generation Approach
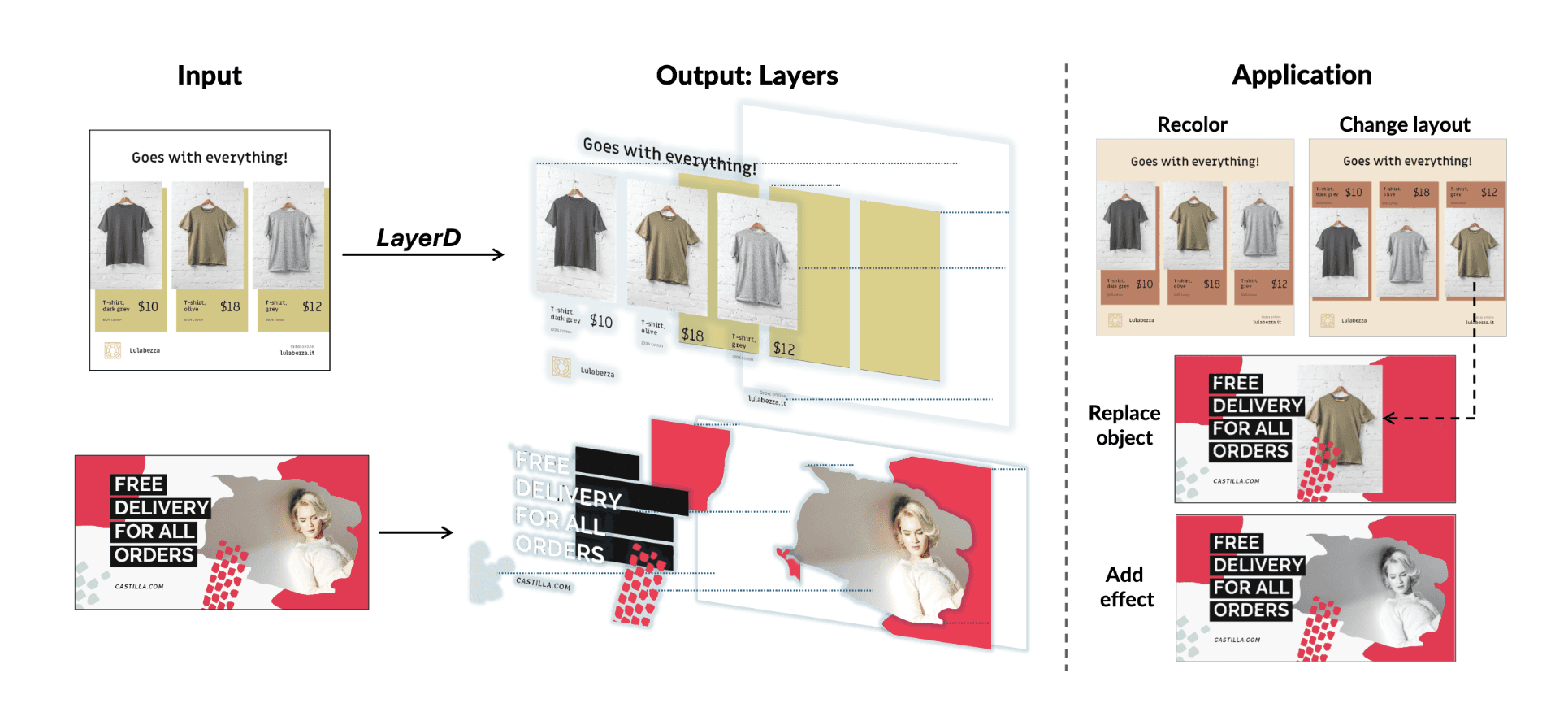
This approach avoids the recursive loop entirely. Instead, it treats decomposition as a generative task, using large foundational models to directly predict a coherent sequence of RGBA layers in a single forward pass.
This attacks the error propagation problem head-on but introduces a new trade-off: Generative Fidelity. Because the layers are often generated via latent diffusion (using VAEs to disentangle RGB into RGBA), the final re-composed image might be semantically cleaner, but the challenge is to get an exact clone of the original pixels. The closer the match to the original pixels, the higher the model's fidelity.

End-to-End Decomposition using Qwen Image Layered (https://github.com/QwenLM/Qwen-Image-Layered)
SOTA models for Image Decomposition
Based on the two methods that we have discussed above, these are some of the SOTA models for Image Decomposition:
| Model | Paradigm | Core Mechanism | Practical explanation for Designers |
|---|---|---|---|
| LayerD | Iterative | Matting + Inpainting | A practical baseline for flat graphics. However, it suffers from error accumulation, one bad mask drifts down the stack, making it brittle for complex transparency. |
| OmniPSD | Iterative | Alpha-Aware Diffusion | PSD-native output that handles transparency better than standard matting. The tradeoff is structure: it is often constrained to fixed types (Text/FG/BG) rather than the arbitrary, variable layer counts designers need. |
| OmniAlpha | End-to-End | Sequence-to-Sequence | Treats RGBA layers as a general modality rather than a pipeline hack. It represents a strong research signal toward foundation models for layering. |
| Qwen-Image-Layered | End-to-End | Variable-Length Diffusion | The closest we have to a Photoshop Primitive. It explicitly targets inherent editability, allowing users to resize or recolor a single layer without the global remixing typical of other generative models. Additionally has support for any number of layer extraction. |
The Takeaway: As the generative models keep on getting better and better, the industry is moving from rigid, stack-based logic (Iterative) toward fluid, more context-aware generative prediction (End-to-End). While Iterative models map to how we think about layers, End-to-End models like Qwen-Image-Layered are proving to be the superior path for preserving the breakdown flow of a scene during decomposition.
Evaluation metric for Layered Image Decomposition
Evaluating decomposition is significantly trickier than standard image generation because there isn't a single "correct" answer. Two professional designers might group elements differently, one might keep text as a single block, while another separates every letter. Both are valid.
Therefore, judging a model solely by the final look is insufficient. We must evaluate if the output behaves like a real design file.
At Lica, to assess the quality of the models, we track two distinct categories of metrics to quantify this:
1. Reconstruction Quality (The Composite)
This assesses how faithful the re-composed image (the flattened stack) is to the original input. This is the sanity check: "Does the output look like the input?"
The Pitfall: High reconstruction scores are necessary but not sufficient. A model could simply output a single "background" layer that looks identical to the input. It would score perfectly on pixel metrics but fail completely as a decomposition tool.
2. Layer Usability (The Structure)
This is the core evaluation. We compare the predicted layer stack against a reference stack, checking for separation quality and logical ordering. Since the number of predicted layers often differs from ground truth, we align stacks using order-aware algorithms like DTW (Dynamic Time Warping) to make fair comparisons.
The Metrics
Here is how we translate these concepts into quantifiable numbers for a production-ready layout:
| Metric | Category | Metric Family | Formula | What We Are Targeting | What "Good" Looks Like |
|---|---|---|---|---|---|
| LPIPS, CLIP | Reconstruction Quality | Perceptual Quality | The "Vibe Check." Ensuring high-level texture and semantic details are preserved, even if pixels drift slightly. | Low Distance. The model captures the "feel" of the texture (e.g., grain, noise) rather than smoothing it out. | |
| PSNR, SSIM | Reconstruction Quality | Pixel Fidelity | Bit-Exactness. ensuring the re-composed image matches the original pixel-for-pixel. | High Score. The re-composed stack should be visually indistinguishable from the flattened original. | |
| RGB L₁ (Alpha-Weighted) | Layer Usability | Layer Fidelity | Clean Cutouts. Measuring pixel accuracy specifically where layers are visible, ignoring hidden transparency. | Low Error. The specific pixels of a cut-out object (e.g., a person) match the source, without "halo" artifacts. | |
| Alpha Soft IoU | Layer Usability | Transparency | Soft Edges. Assessing how well the alpha channel captures complex semi-transparency (hair, glass, shadows). | High Overlap. The mask isn't just a hard binary cutout; it preserves the gradient of shadows and fine details. |
Takeaway: A truly useful model must score good on both sets of metrics! It needs to look like the original (Reconstruction) while providing a clean, separated stack structure (Usability).
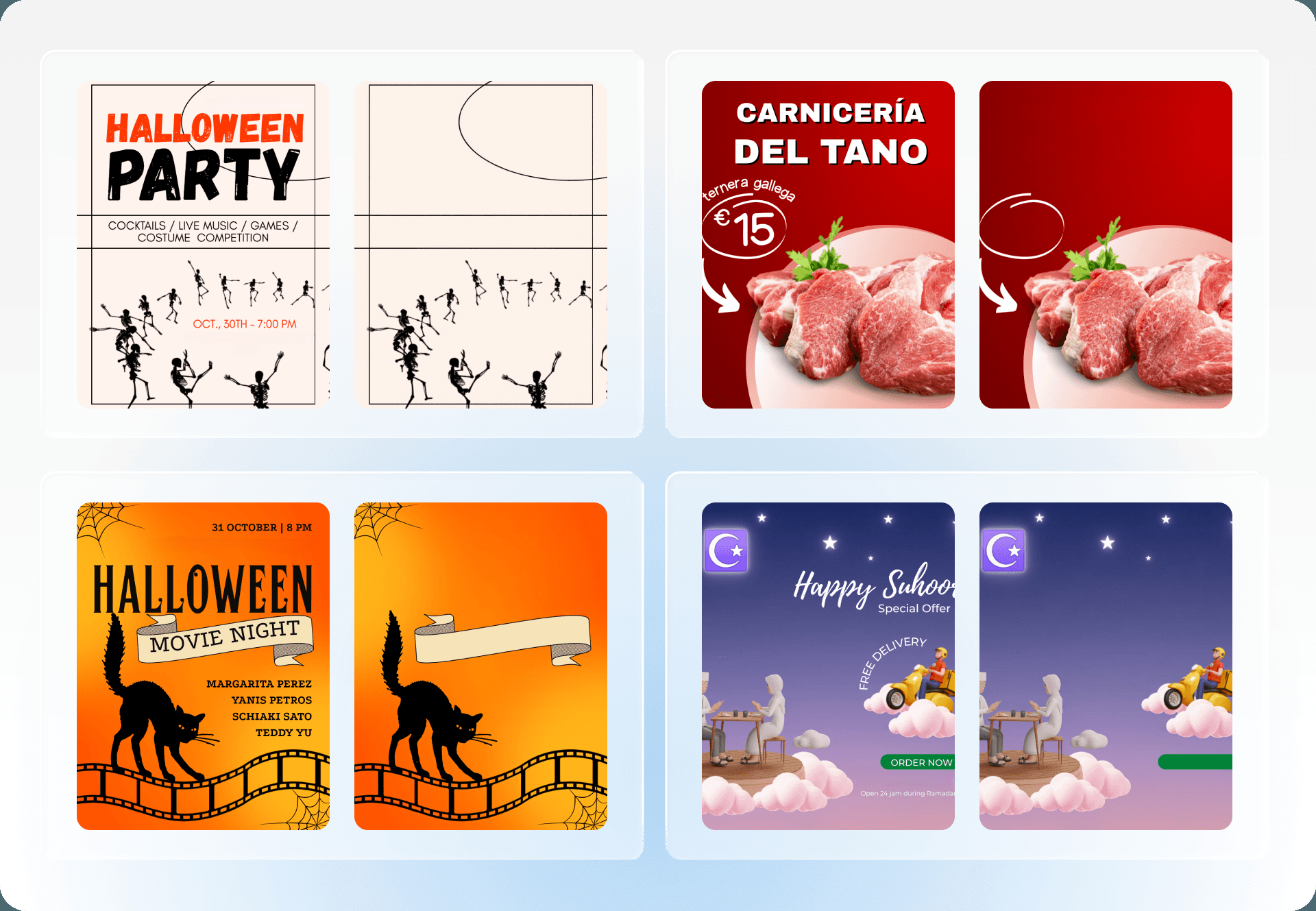
Here are a few examples of decompositions produced by our trained models:
Training and Benchmarking models
At @Lica, we are building models across both recursive decomposition and end to end generation workflows.
In this work, we present benchmark results for our specialized recursive modules, specifically the Text Eraser and Object Eraser.
As noted, the recursive approach lives or dies by its ability to "heal" the image accurately at every layer early on. When you extract a layer, you leave a hole. If the system fails to fill that hole plausibly (inpainting), the error propagates downward, ruining the fidelity of the layers beneath. To prevent this, generic inpainting models weren't enough for decomposition tasks. We trained two specialized models to handle this:
- Text Eraser: Specialized in extracting typography while reconstructing complex backgrounds behind thin, high-frequency character strokes. We erase text because its properties are predicted separately by another model that we have trained, allowing the text layer to become truly editable rather than just another extracted 'image'.
- Object Eraser: Designed to cleanly remove semantic objects from the text-clean image and generate the occluded geometry behind them.
Below is how our specialized modules stack up against current state-of-the-art inpainting models and commercial APIs. We specifically selected Google Eraser, Omni-inpaint, and Bria 2.3 for comparison as they represent the most widely adopted industry standards for high-fidelity removal tasks.
1. Text Eraser Benchmark
| Metric | Ours | Google-Eraser (Paid API) | Omni-inpaint | Bria 2.3 Remover |
|---|---|---|---|---|
| Reference Free-Metric | ||||
| Remove (↑) | 0.9411 | 0.9134 | 0.8993 | 0.9014 |
| Reference based Perceptual-Metric | ||||
| LPIPS (↓) | 0.0189 | 0.0398 | 0.1073 | 0.0747 |
| CLIP_SCORE (↑) | 0.9881 | 0.9609 | 0.9132 | 0.9171 |
| DINO (↑) | 0.9833 | 0.9544 | 0.8828 | 0.9216 |
| Reference based Reconstruction-Metric | ||||
| PSNR (↑) | 37.44 | 34.642 | 23.035 | 31.288 |
| SSIM (↑) | 0.9750 | 0.9578 | 0.8994 | 0.9014 |
Before-and-after results demonstrating model performance in text erasure.
2. Object Eraser Benchmark
| Metric | Ours-Base | Google-Eraser (Paid API) | Omni-inpaint | Bria 2.3 Remover |
|---|---|---|---|---|
| Reference Free-Metric | ||||
| Remove (↑) | 0.87623 | 0.74725 | 0.85678 | 0.84988 |
| Reference based Perceptual-Metric | ||||
| LPIPS (↓) | 0.03988 | 0.13770 | 0.14860 | 0.07980 |
| CLIP_Score (↑) | 0.94907 | 0.89276 | 0.81929 | 0.88805 |
| DINOv3_Score (↑) | 0.82962 | 0.65704 | 0.60298 | 0.72506 |
| Reference based Reconstruction-Metric | ||||
| PSNR (↑) | 35.1444 | 26.5327 | 22.04771 | 32.3006 |
| SSIM (↑) | 0.94887 | 0.88080 | 0.83681 | 0.90835 |

Before-and-after results demonstrating model performance in object erasure.
Conclusion
The shift from "generative AI" to "generative design" hinges on solving the image decomposition problem. As we've explored, the industry is moving away from purely creative, stochastic generation toward structured, deterministic outputs. This transition is technically demanding; it requires moving past simple pixel generation to a system that understands the semantic and structural hierarchy of a layout.
Our approach centers on three technical pillars that we believe define the next generation of design tools:
- Multi-Modal Disentanglement: By successfully isolating vector graphics, text, and raster images into independent, high-fidelity layers, we eliminate the "locked screenshot" problem. This allows for a hybrid workflow where AI handles the heavy lifting of reconstruction while the user retains control over discrete design elements.
- Metric-Driven Development: We believe that traditional generative metrics are insufficient for professional work. By prioritizing Layer Usability family metrics (such as Alpha Soft IoU and alignment via Dynamic Time Warping) we ensure that our models don't just produce "pretty" results, but technically sound, production-ready files.
- Benchmarking Performance: Our specialized Text and Object Eraser modules are currently outperforming industry benchmarks like Google Eraser and Bria 2.3 across both perceptual (LPIPS, DINO) and reconstruction (PSNR, SSIM) metrics. By minimizing error propagation during the "segment-erase-generate" loop, we've achieved a level of fidelity that makes professional iteration possible.
The path forward for design AI isn't just about higher resolution or better prompts. It is about building a robust architectural bridge between latent diffusion and structured design layers. We are committed to refining these decomposition pipelines so that every AI-generated pixel remains a controllable, editable, and professional asset.
References:
- https://medium.com/dsgnsync/the-80-20-rule-in-design-simplify-optimize-and-thrive-2d12e5a9cafa
- https://en.wikipedia.org/wiki/Dynamic_time_warping
- https://cyberagentailab.github.io/LayerD/
- https://github.com/QwenLM/Qwen-Image-Layered
- https://showlab.github.io/OmniPSD/
- https://github.com/Longin-Yu/OmniAlpha
- https://huggingface.co/briaai/BRIA-2.3-Inpainting
- https://docs.cloud.google.com/vertex-ai/generative-ai/docs/image/edit-remove-objects
- https://github.com/advimman/lama
- https://github.com/richzhang/PerceptualSimilarity
- https://github.com/OpenAI/CLIP
- https://aclanthology.org/2021.emnlp-main.595/
- https://www.cns.nyu.edu/pub/lcv/wang03-preprint.pdf
- https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio